
I generally try not to recommend newly added features right away. Going by the experience, new features require time to stabilize and some wrinkles to be ironed out. However, occasionally, vendors come up with some quite interesting features. And being a combination of a data scientist and an engineer, I cannot stop myself from trying to remove layers of abstraction and figure out what that functionality is doing. The new AWS Redshift ML is one such feature.
Launched in December 2020, the feature is still in preview. In its release note, AWS has stated that “Amazon Redshift ML makes it possible for data warehouse users such as data analysts, database developers, and data scientists to create, train, and deploy machine learning (ML) models using familiar SQL commands.”. It also mentions that this functionality is provided by leveraging AWS Sagemaker. Since I have used Sagemaker for multiple projects, I wanted to check what this feature does on Sagemaker end to enable this functionality.
The basic setup required for this feature looks quite straight forward. Just go through following steps.
- Create a new Redshift preview cluster- Makes sense to have new cluster instead of tinkering on a running one and potentially cause problems. Plus, the cluster needs to be in ‘Preview’ Maintenance mode with maintenance track selected as SQL_PREVIEW. Ensure that this is selected during creation of cluster. Here’s how you do it on create cluster page:
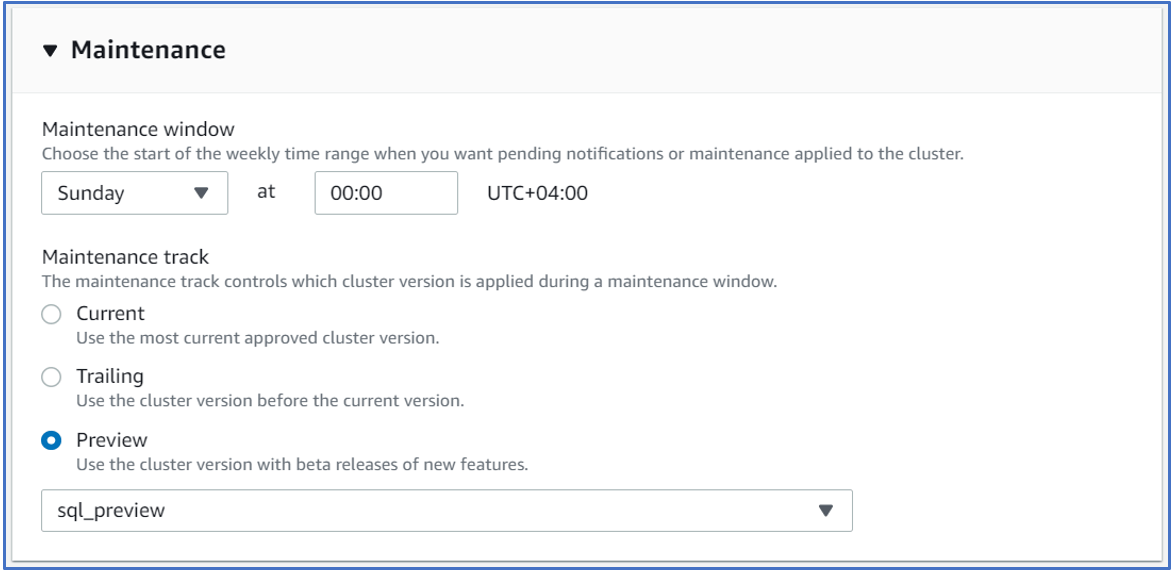
I chose simple dc2.large core since I was not looking to incur lot of costs for this little experiment.
- Permissions: The role registered on Redshift cluster should have ‘arn:aws:iam::aws:policy/AmazonSageMakerFullAccess’ policy attached. Obviously, it is a sledgehammer approach. If you are looking for something more ‘clinical’ refer to the guide here. It also needs S3 and Redshift admin roles to do its magic.
- Also, you need to add trusted relationship so that your service role can wear the ‘Sagemaker Admin’ hat.
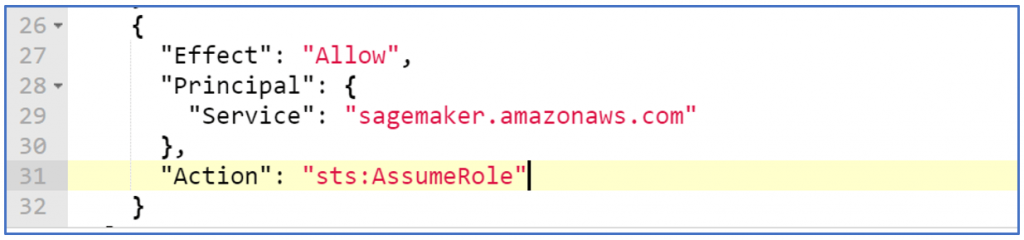
And that’s it. Simple enough isn’t it? So far so good, Lets go to actual feature then. The main idea which AWS tells us is – ‘Hey, wouldn’t it be awesome if you could create a ML model, which chooses the algorithm, optimizes and deploys it for usage as a SQL function simply by using a SQL command?’. Well, that’s what it is expected to do at least.
After the cluster gets setup following steps will get you to the model creation and optimization step.
- Create a table and load sample data: I was tempted to use the ‘sanitized’ data set provided by AWS to try out the feature. But then I though, let’s make things interesting with my own simple dataset. This step is as simple as it can get, here’s the code:
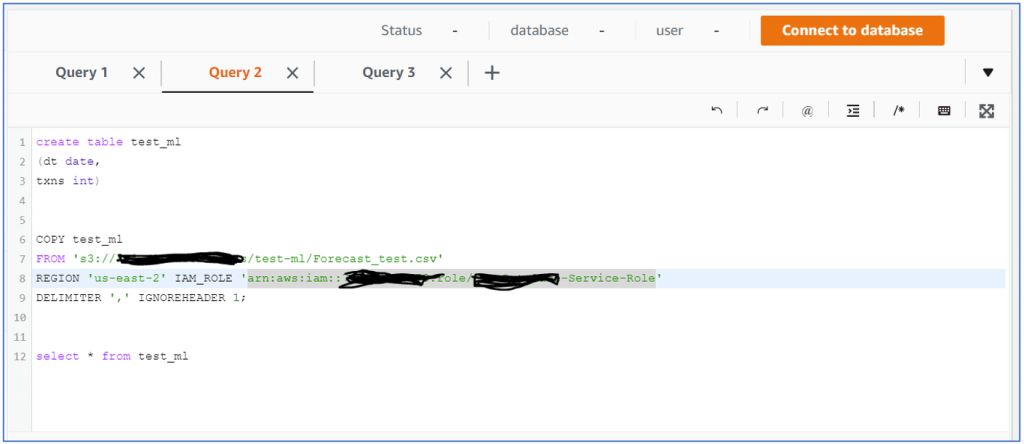
I have my table and my data is loaded. We are looking at a simple time series data which I am planning to use for forecasting. Since the documentation for this feature is still not very detailed, I thought why not find out if the feature can do something which is not in sample? (sample data is about customer churn use case)
- Now comes the real magic. Just like any other create command, Redshift ML introduces ‘CREATE MODEL’ command (you need ‘Create Model’ permissions to execute, please refer to documentation for details). In the command you must specify the sample data, the target variable and few other things. Following is the detailed command:
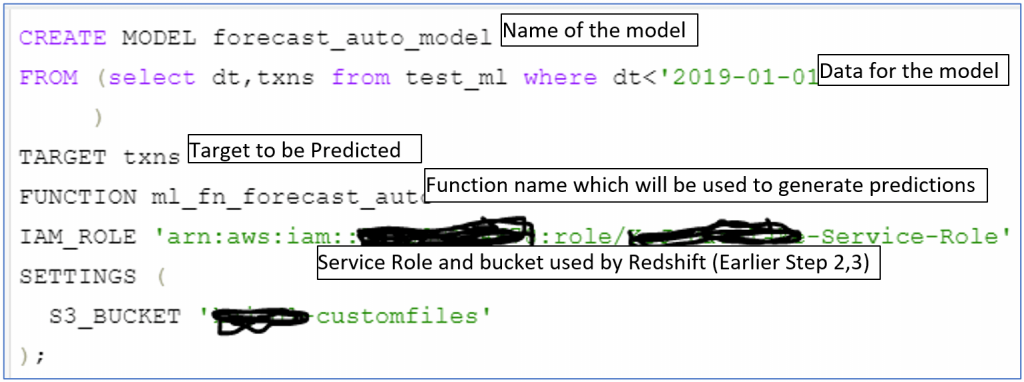
The supplied data must have two variables, one of which must be target. If you want you can add more cross-sectional parameters, but I have enough to see what comes out at the other end. Also, not sure what happens if one wants to create unsupervised learning model (may be subject for a later blog)
Just when I had started getting that “either it is really that simple or am I missing something big” feeling, I encountered below error while running above command:

So, no support for time series, that’s bad. Coz I had spent time on that dataset. Undeterred, I converted the date column to ‘yyyymmdd’ to see if I can fool the db into giving me nice forecast (bearing in mind that It will not give me any useful insights about the predictive accuracy of the feature. But still, I can explore usability and effectiveness). So now I run:
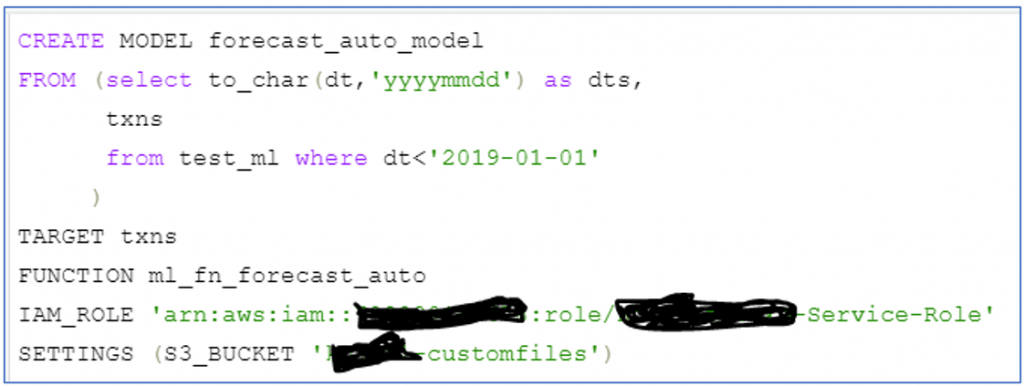
And it took the bait. If you notice I am holding out some data from dataset so that I can use it for prediction later. The command succeeded and I could see the model in ‘Train model in progress’ status in svl_ml_model_info (new table created by Redhsift for this feature).
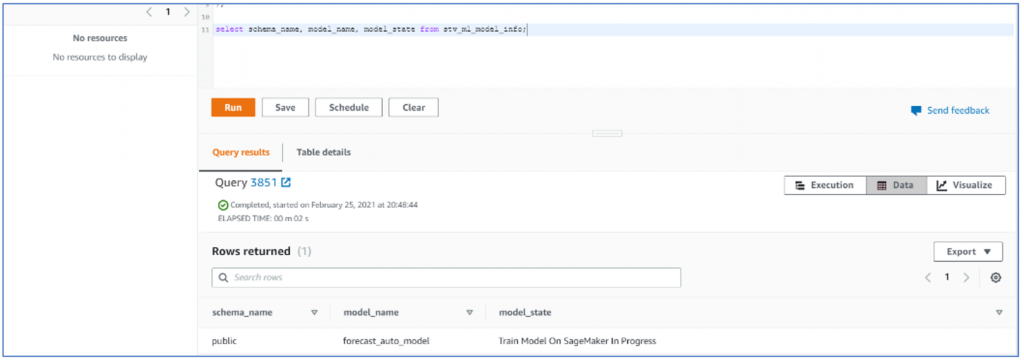
Now it was my chance to see what it was going to do in Sagemaker, without wasting time I jumped right into sage maker to see if any new models had started training. To my surprise there weren’t any, First I thought they must have done something clever to hide the process from me. But little bit of digging and I found a ‘processing’ job
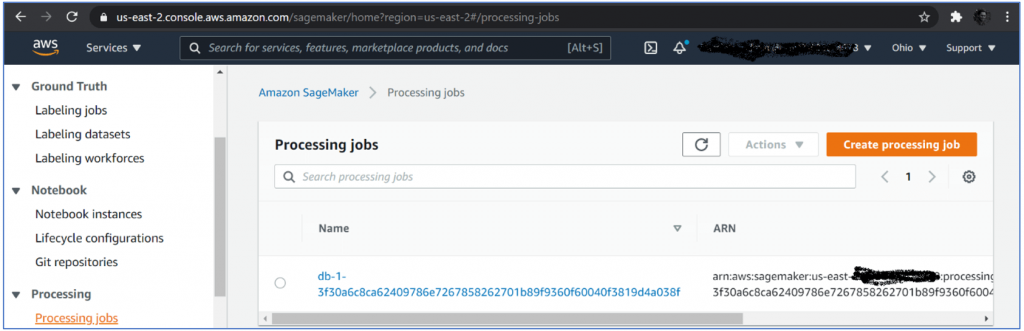
Then in no time there were two processing jobs:
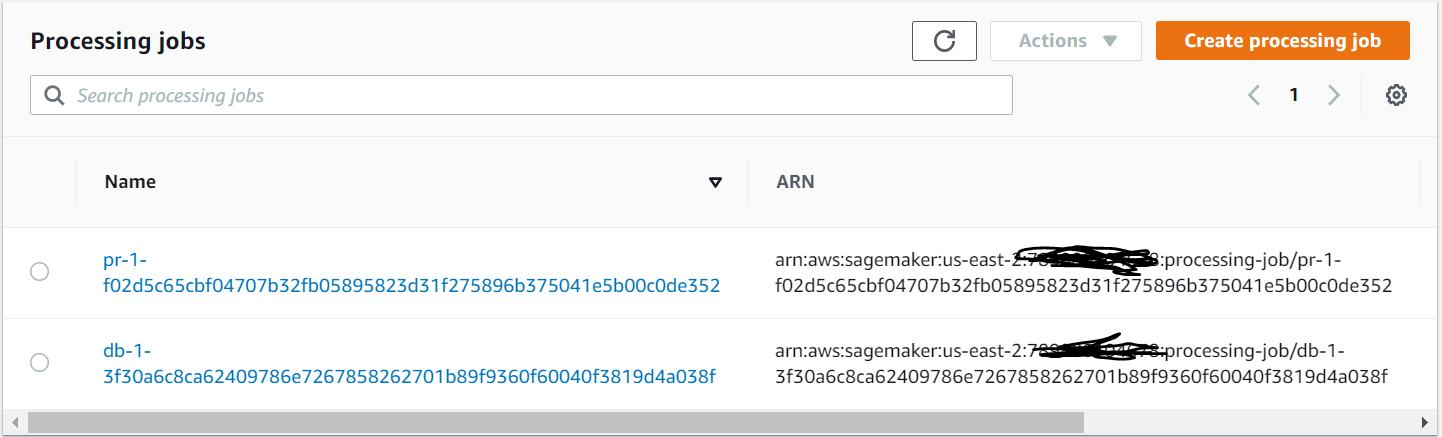
What were those jobs doing? good question, the first one (starting with ‘db’ which had run first) was a ‘data splitter’ job. Looks like it is using one of the pre-built ECR images (mostly using scikit). I am going to go out on a limb and say it was splitting test and train dataset for tuning.
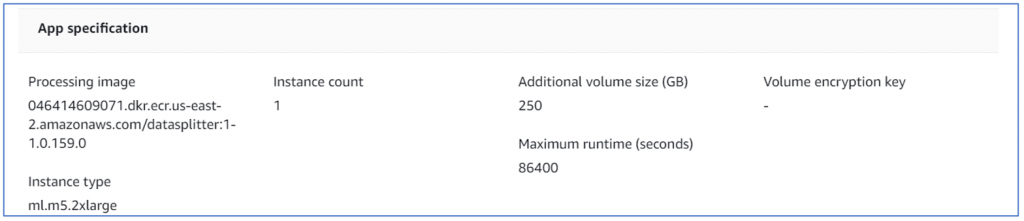
Second one (starting with ‘pr’) is pipeline recommender again using docker ECR image, looks like it is using scikit’s famous preprocessing ‘pipeline’ class which does several standard transforms on the data to get it to ‘modellable’ state. But then this is just a guess.

After the jobs were done, then came the real deal, I could (finally) see the training job, what was it doing? It was using good old scickit-learn-automl. For the uninitiated, it is a well-known and quite useful automated machine learning toolkit which, based on the data, can figure out suitable algorithm to be used on its own and build the model after that. Powerful stuff.
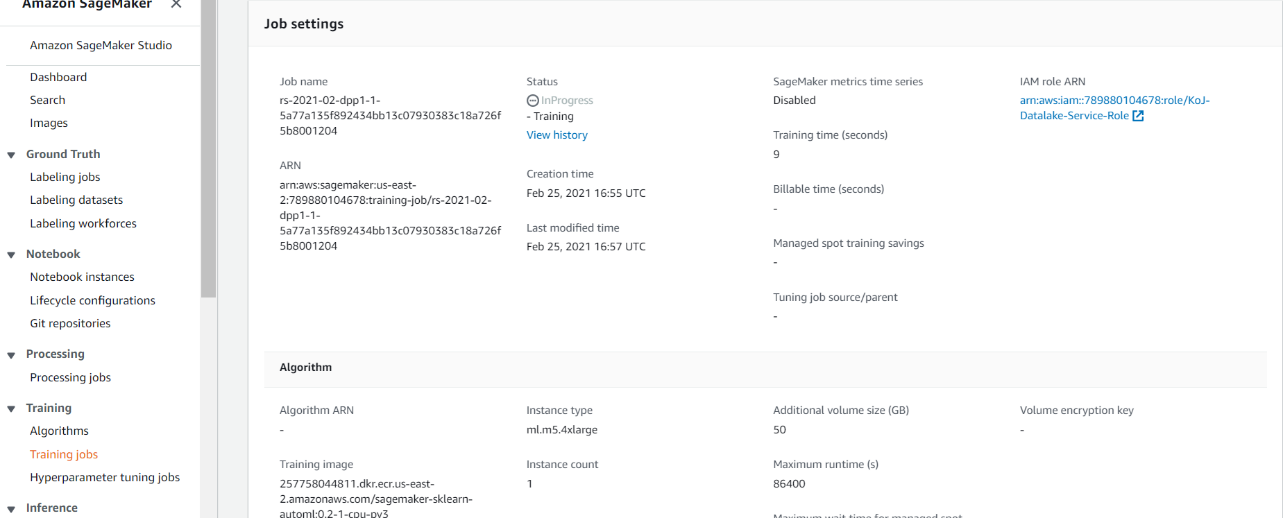
After the model was build. It went ahead and submitted a hyperparameter tunning job with 250 model runs (that’s going cost me).
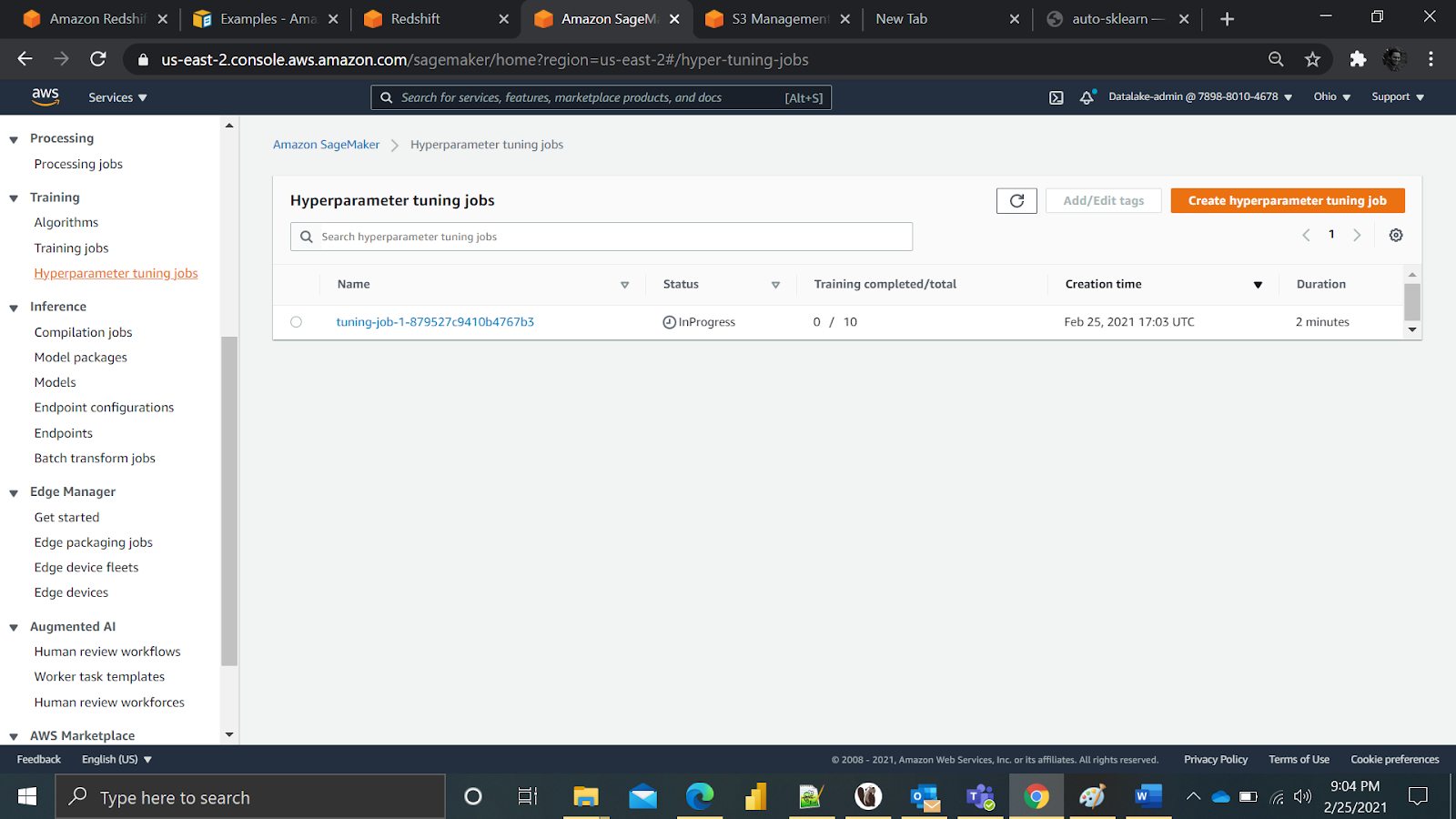
Again, for everyone’s benefit, hyperparameter tunning is useful feature in Sage maker which allows user to create several model trainings jobs with aim of some target variable. It also provides ability to give ranges to hyper parameters. Let’s look at what this tuning job is doing.
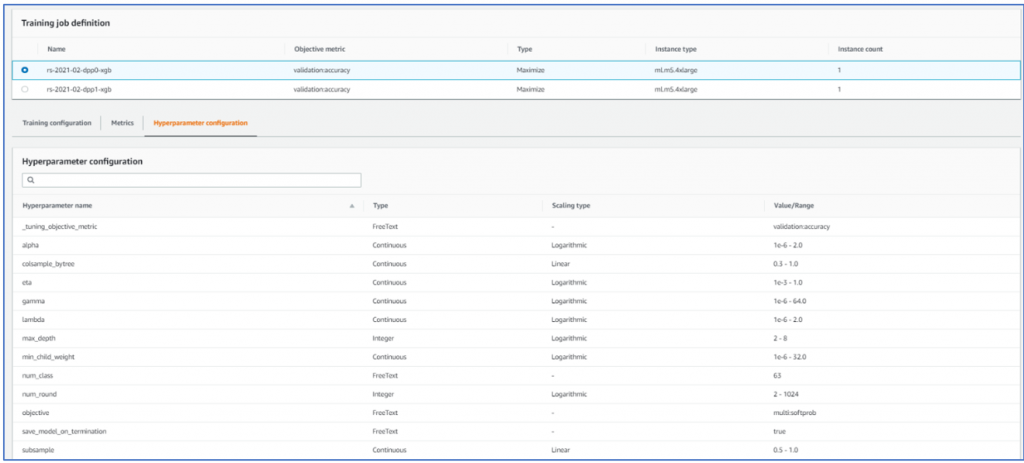
Well, I would love to explain each parameter in the list but I myself am no authority on these parameters. You can check how deep the rabbit hole goes. Suffices to say that it is important to find values for these parameters which works best for your data and hyperparameter tuning will help you homing in on the optimum parameter values with desired objective (look at topmost row in the table which says ‘validation accuracy’)
Here’s what hyper parameter tuning job came up with for my data:
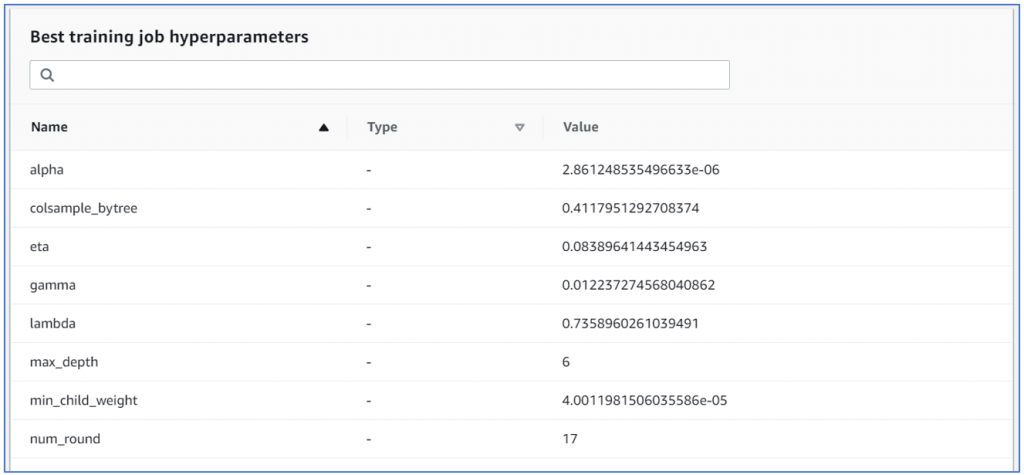
These set of parameters represent the values which resulted in best objective value. The objective was validation accuracy which did not get a great result (a pedestrian 9%) but I guess that was because I was making it do something it was not equipped to do (forecasting based on dates which do not look like dates) also the data splitter may have randomly done a test and train split without honoring dates. So very little control on how the engine will create and evaluate model. The example data gives use case which is suitable for this type of modeling and evaluation, hence it will give quite good results. May be if we can split date into year, month quarter etc. we might get better results (again subject for later blog). Still not being able to control data splitter will be a problem.
The model resulted from these parameters was chosen by the Redshift ML to be used with my function on db. The status of my model went to ‘Model is ready’ only after hyperparameter tunning was complete (almost 75 minutes for very small data).
I also noticed several other things which sage maker did. It created 3 compilation jobs (preprocess, Model and postprocess) so that the model can be deployed on any linux-x87_64 machine.
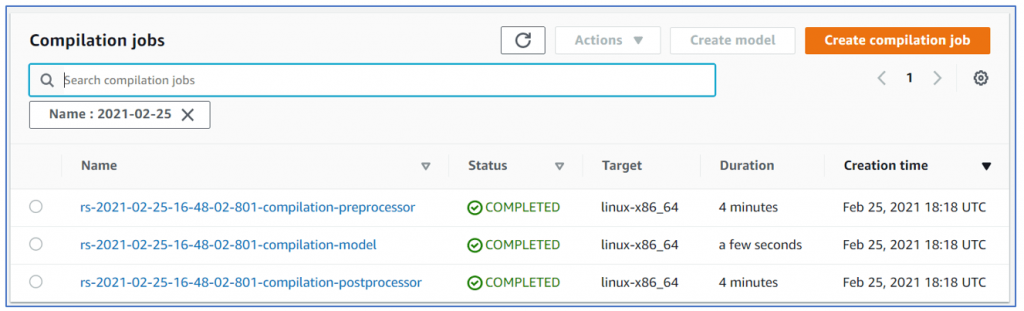
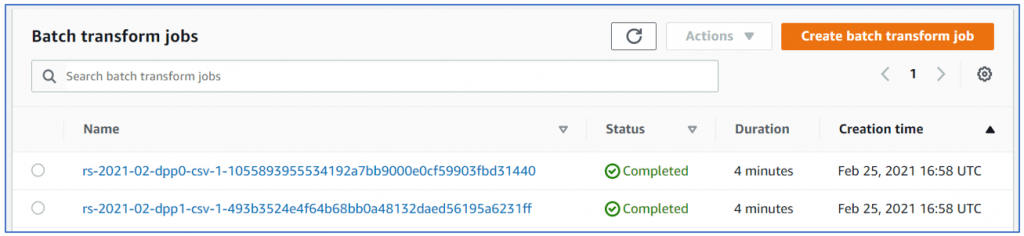
Also, it had created a batch transform jobs so that inference can be created without deploying a persistent endpoint. I guess that’s how the model ‘function’ will return results (without endpoint):
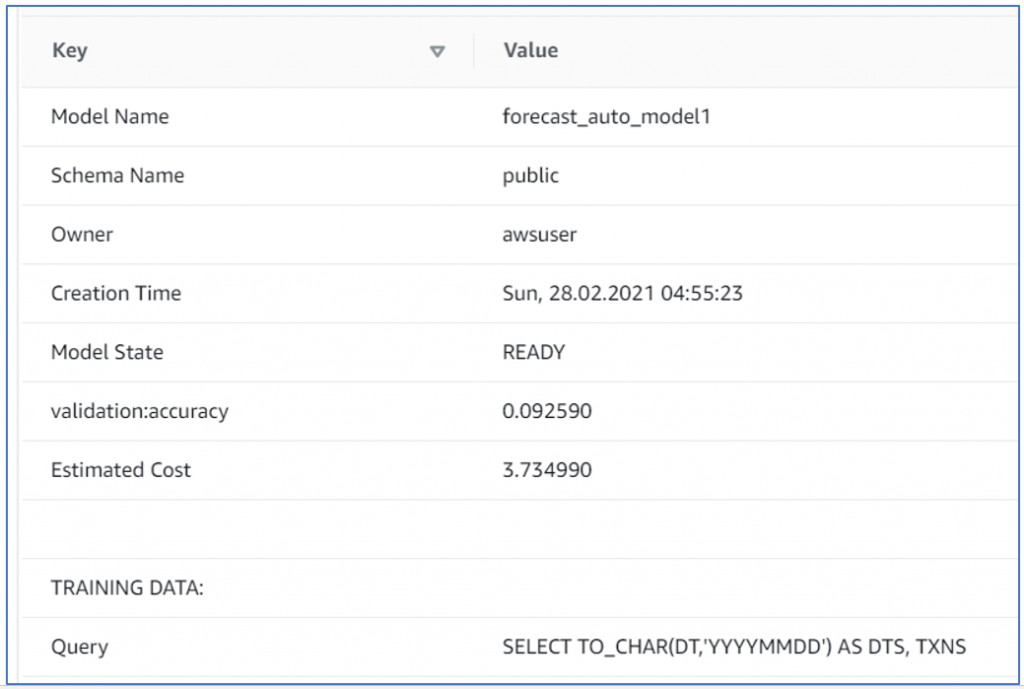
There is a show model command which also shows some good details. Simply run ‘SHOW MODEL <your model Name>:
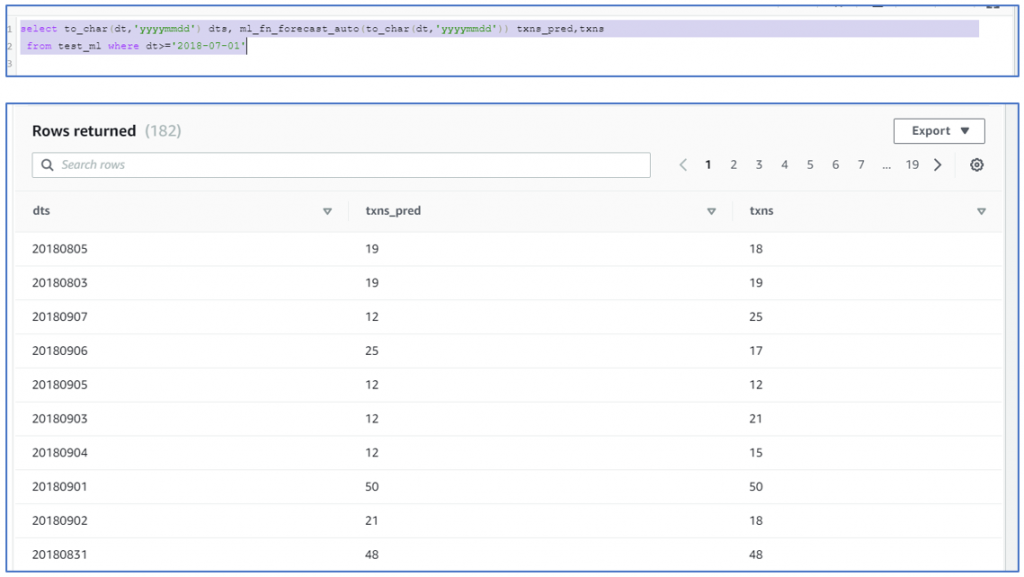
After this it is quite easy to get results of the of the forecast. Just use the function name mentioned in the model and pass the date to it. Out comes the prediction.
Final verdict, it is indeed very useful feature. As demonstrated during innovate, I liked the idea of inline sentiment analysis on text data. I can see how it will be useful for some real time applications. Also, there are Aurora ML and Athena ML, so these features are being added to multiple tools. Will be interesting to see if they support spectrum as well. Also as demonstrated above, it is quite easy to setup so may not create lot of admin and development overhead.
Having said that there is very little control over model creation and evaluation process. This will have an impact on the accuracy and stability of the model over a long time. Also, I think couple of more features will really help its usability:
- It would be good to have some kind of ‘REFRESH MODEL’ command so that it will run hyperparameter tuning again and allow us to tune the model.
- Just as sage maker allows us to deploy our own model as a ECR docker image and then use it on the end point, this feature should also include ‘bring your own model’ option and allow users to access the function at runtime.
Give it a spin but let’s not assume that this will solve all your problems.










