
The disciplines of data and decision science are being used widely used to solve business problems. While there are quite a few similarities between these two, there are also key differences. Here we have tried to look both similarities and differences and then illustrate these approaches with a practical example to drive home the point.
Data science looks at the data as an input to generate multiple insights. These insights are generally not bounded by much of business context. E.g. high negative skewness value of invoice sales amount may not carry much of a business significance, yet a data scientist will look at these with great interest as an intermediate step towards more valuable insight or even present it as an insight on its own. Thus, data scientists will present all their findings as a set of insights which can then be evaluated for their business value. This set of insights will ultimately be outcome of a data science experiment.
Decision science on the other hand starts with a business problem which warrants a decision. The data analysis and the insights generated will be tightly bound by that business problem. Any line of analysis which is not related to the business problem, will not be rigorously perused. Thus, outcome of decision science experiment will be a recommended decision and, preferably, basis for the recommendation and projected outcomes.
Obviously, irrespective of what the starting point and end objectives of data vs decision science are, many of the steps taken by both will be very much aligned. Both will perform largely similar analysis of data. In many cases, data scientist might stumble upon same insights as decision scientists. However, decision scientists will quickly zero in on the analysis which leads to required outcome as opposed to data scientists, who would tend to follow all leads looking to generate as many insights as possible.
Let’s take a quasi-real-world case to further understand differences between data and decisions science. Let’s look at a hypothetical cosmetics retailer called Forher beauty products. Forher is a major player in the region and sells basic make up and other personal care products online. Forher beauty products has embarked on data and decisions science experiments simultaneously. The CDO of Forher is not sure if they should pursue data science or decision science and wants to see each in action before making an informed decision. The CDO gives 6 months’ worth of sales data to both teams. Let’s call them data and decisions teams.
Data Science Process.
Data team started off by fetching the data and performing basic checks like number of NA values data distribution etc. Eventually, they decided to follow 3 lines of investigation:
- Time series analysis of data for forecasting
- Identify major factors affecting sales figures
- Identify how to influence major factor affecting the sales.
Attached notebook and data file will provide you with required code which details out this analysis. Some of the main findings are as follows:
The time series is largely static, trend and seasonality signals are quite weak. Also, there are no cross-sectional parameters which can be used. Unit prices of all products are static over given time period.
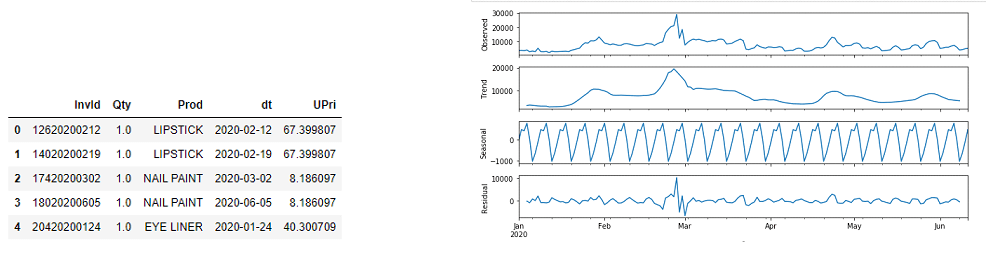
With this kind of data we might be tempted to use techniques like ARIMA or ETS to calculate forecasts. However, since we don’t have a full year worth of data, it will not be wise to use this kind of data for forecasting.
Looking at trends of total sales, number of transactions and average transaction value. It seems like number of transactions per day are limited (this might be data manipulation from Foreher). So only way by which we can increase sales is if we increase average transaction value.

Looking at these it seems like increasing average transactions value will give us required push to get more sales. Let look at Pareto distribution:
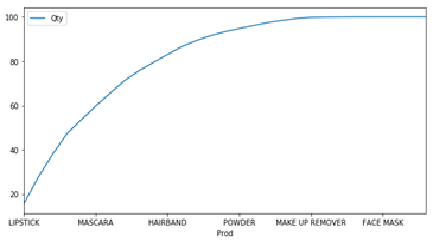
Looks like 30% products are generating close to 80% sales.
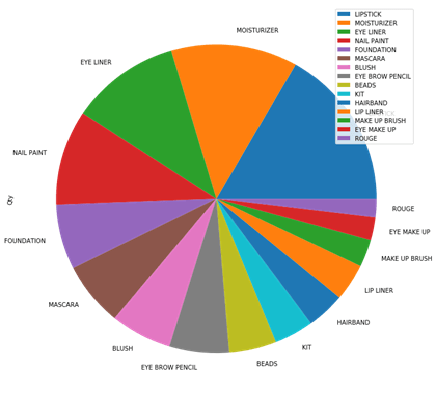
Clearly Lipstick, Moisturizer, Eye Liner and nail paint are most popular products. We can focus on these products to further improve our sales.
One of the ways to improve transaction value is to create products bundles which would fetch higher value and will have positive impact on average transaction value. Let’s see which combinations are most widely sold:
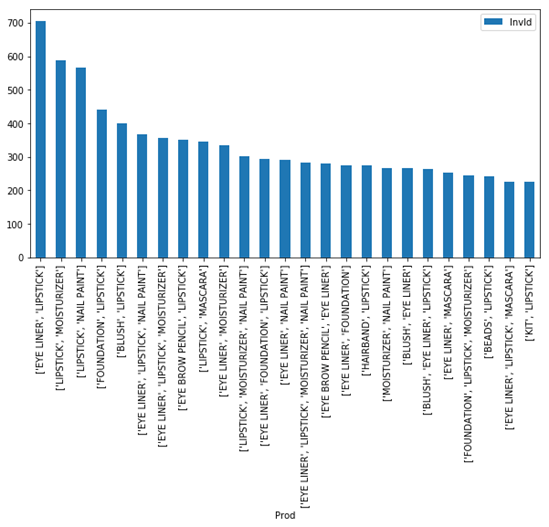
Naturally combinations of most widely sold products are also most widely sold. Let’s look at which products are most often found in combinations:
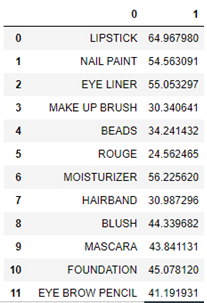
Looking at this analysis, we can perform association rule mining to identify correct product bundles.
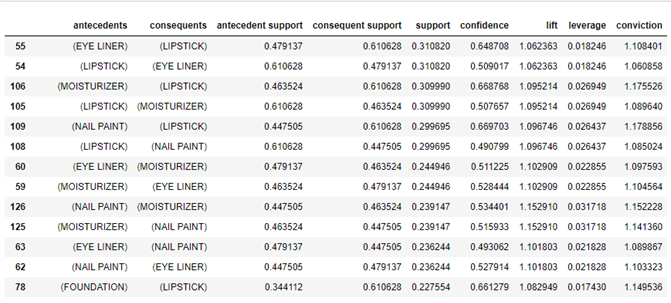
Confidence is hovering around 50 to 65%, which indicates that there is significant reason to believe that there are some sales which can be improved by creating combinations like Eye Liner + Lipstick, Nail Paint + Moisturizer will provide higher sales.
Of course, we can analyse the data further and try to get more insights. But by now, you must have got an idea of how data science team will go about doing their analysis.
Decision Science Process
As stated earlier, decision science starts with a stated business problem, here the business problem was as follows.
What combination of products sold as a bundle at what prices will give us maximum uplift in terms of sales.
As you may have guessed by now, the stating of the problem narrows down the trains of analysis considerably. Of course, some of the initial analysis will look like data science process. E.g. here as well we will look at most widely sold product combinations.
However, since here we are looking for maximum uplift, lets look at products which have maximum unit price, that way when we add those products to combinations, we will see higher sales uplift.
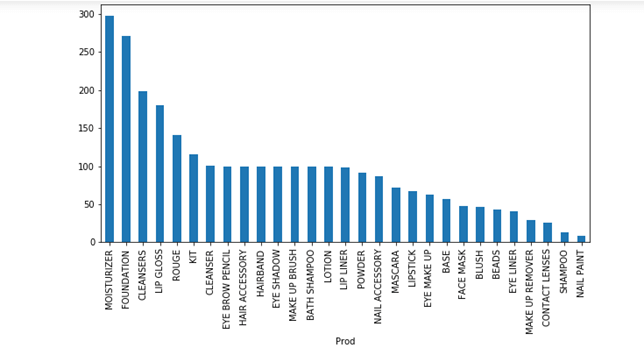
Looking at the price, it will be beneficial if we add high prices products to the bundles so that we get maximum uplift. Here we should look at Moisturizer, Foundation and Cleansers as highest priced items. Let’s look at total quantity sold by product.
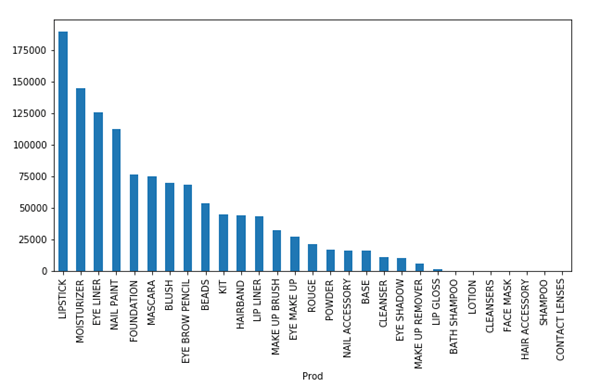
Looks like we can do well on sales if volume of foundation sales can be improved. It has higher unit price but lower volume. If
Here decision to look at association rules is quite straightforward as problem statement clearly talks about product combinations. Then we can focus on the problem at hand rather than following other analytical paths.
Coming back to analysis, since we mainly want to look at combination deals with Foundations, we will only look for association rules which have this product as consequents.
Foundation combinations:

We can create a combination of Lipstick + Foundation, Eye Liner + Foundation for 299 and 249 respectively. This will encourage buyers of Eye liner and lipstick (which represent 60% of all transactions). Also, currently 37% of Lipstick and Eye liner customers anyway buy these products together. For a lower priced product bundle the sales are most likely to increase.
Obviously, in a typical business scenario there will be several additional factors which have to be taken into consideration (margin per product, positioning, premium vs economy etc.) before we arrive at decision on which products to sell as a combo. However, using decisions science we can arrive at most beneficial combinations.
Real life scenarios will demand in-depth analysis and more valuable insights. But, looking at this example will give you a good idea of what data and decision science can do for your organization.
Get in touch now to know more.











This Post Has One Comment
It’s amazing to visit this web page and reading the views of all friends on the topic of this article,
while I am also zealous of getting familiarity.